
Oct 16, 20071 min read
Eclifox - the publicity
Wow! Never imagined this would happen so soon. Oct 16th: Eclifox is currently in the front-page of . The number of Google results for 'eclifox' is 12,200. Before Eclifox was released it was around...
Page 8 of 25
Wow! Never imagined this would happen so soon. Oct 16th: Eclifox is currently in the front-page of . The number of Google results for 'eclifox' is 12,200. Before Eclifox was released it was around...
So here I was conducting yet another workshop on Eclipse. This time it was in IIIT Bangalore. The campus is great, so are the students. It was the most interactive session I have ever been to. The...
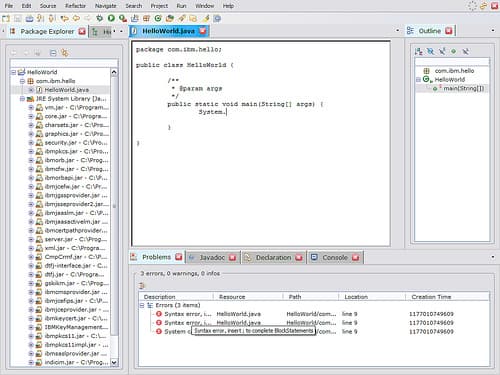
We finally made it! is now an technology. So what is Eclifox? In order to understand what Eclifox is, look at the screenshot below: What do you see? If you think that this is the screenshot of the...
Two of my colleagues and friends Vamsi & Shiva, who are committers on will be conducting training sessions at / . Java EE 5 App Development on Geronimo 2.0 simplified using Eclipse by Shiva Kumar A...
I was part of a team of three (myself, Sayeed Sanaullah and Gaurav Bhattacharjee) from ISL, who conducted a one day workshop on Eclipse in Vishwakarma Institute of Technology, Pune. We had 3 theory...
I delivered a lecture on "Introduction to Eclipse and its usefulness" in , a distance learning program of . This is the first time I am delivering a lecture in VTU Edusat. Here is what I liked abou...

I had been to Sankey Tank today to experience the sunset and also click a few pictures.
This was one feature that I was missing in Google Reader. So, while I tried when I really missed it, I was not quite happy with it, since it was showing up really old posts and there was no obvious...
The IPv6 specification has been around for . People understand the problems with IPv4. Yet the world is struggling to move to IPv6. Ruby has been around for . It had enough time to evolve before it...
Ever thought you are so addicted to Java that although the world is talking about moving to functional languages, you just cannot see yourself leaving the JVM? Well, , could be your solution. You c...
Just realized that my paper on has finally been published.

With 5 movies and a solo trip on my bike around Bangalore on the ring road, clearly, this is one of the most productive weekends ever! :) Movies I watched: - Cast Away - Forrest Gump - Road to Perd...